Audio Interaction Model
Fully OpenThe next-generation audio-language model. A streaming brain for interaction.
1NTU 2NUS 3CUHK
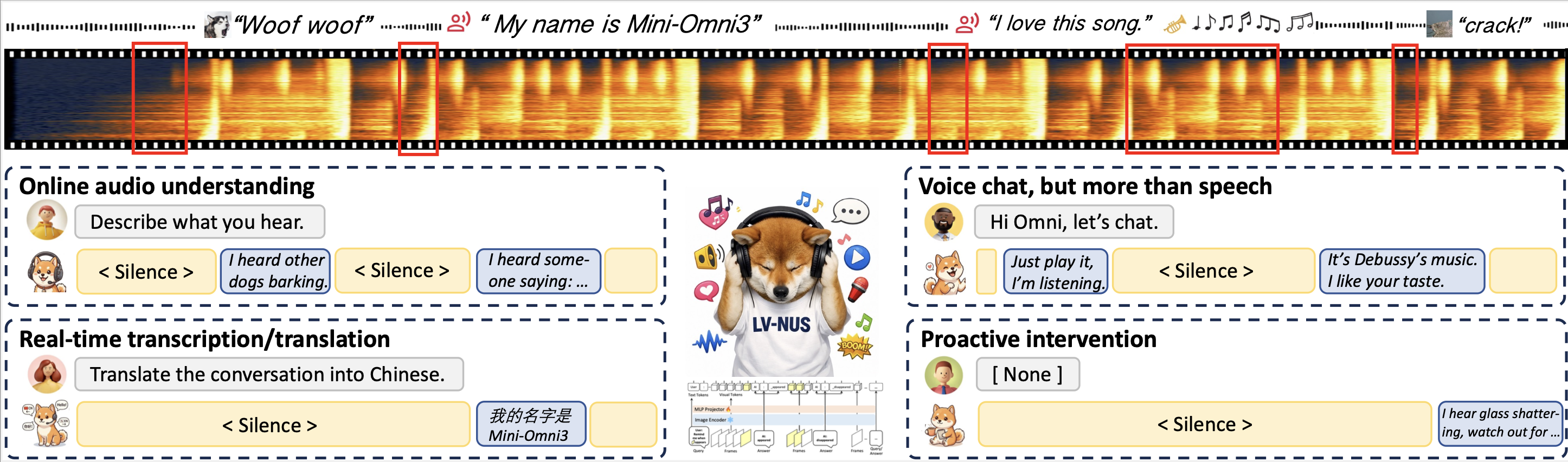
Audio is an inherently interactive modality, yet today’s Large Audio Language Models are offline, and streaming ones each handle only a single task such as streaming ASR or voice chatting. We formalize a new paradigm, the Audio Interaction Model, and realize it with Audio-Interaction: a unified streaming model that, through an always-on perceive-decide-respond loop, listens to sound, environment, and instructions in real time and decides on its own when to respond from the semantics of the stream. A single architecture unifies all offline and real-time tasks and gives rise to many new capabilities.

Watch Audio-Interaction listen, decide and speak, live
Comparison with SOTA Streaming Models
Same continuous audio stream, three models side by side. Each receives identical input; only Audio-Interaction emits a meaningful, round-by-round response as each event lands.
| Clip | Audio-Interaction[Ours] | gpt-realtimeby OpenAI | seeduplexby ByteDance Seed |
|---|---|---|---|
| sample_count.wav Counting a repeating sound, live |
once!/twice!/three times!/four times!/five times!
|
<Empty>/<Empty>/<Empty>/<Empty>/<Empty>
|
<Empty>/<Empty>/<Empty>/<Empty>/<Empty>
|
| sample_music.wav A cough, then background music |
It sounds like you're coughing; please take care and drink some water./The style of the music clip is likely jazz, characterized by its instrumental focus on improvisation and complex harmonies.
|
<Empty>/I can tell you whether I think a piece of music is effective, interesting, well-crafted, emotionally expressive, etc. But I don't have personal likes or dislikes.
|
<Empty>/<Empty>
|
SoundFlow: training models with an always-on perceive-decide-respond loop
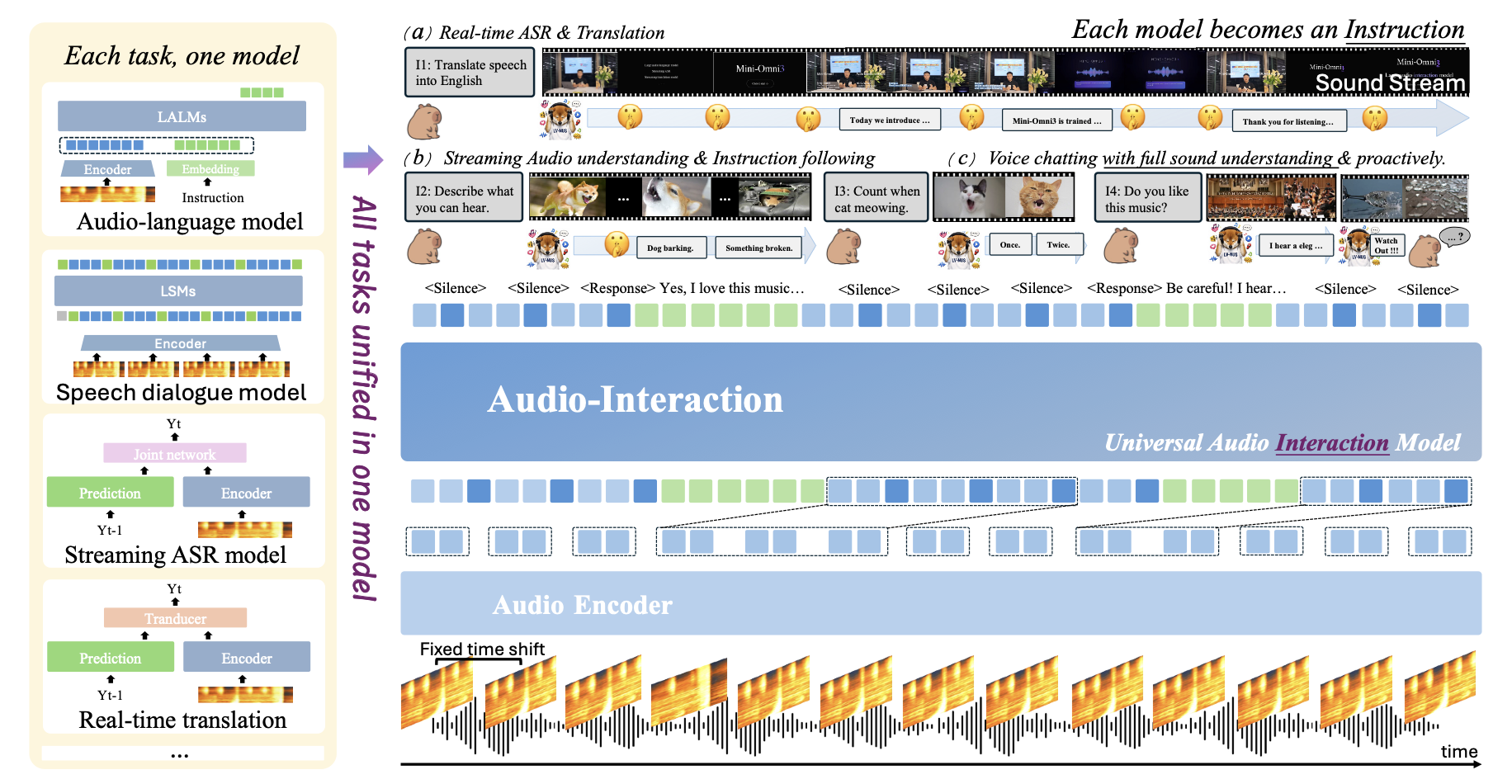
The real world never pauses to hand over a finished clip, so an interaction model has to keep listening and decide for itself, instant by instant, whether this moment deserves a reply. That moves audio modeling from answering finished clips to running a continuous loop, and from a stack of single-task models to one model where recognition, translation and dialogue are all instructions inside the same always-on stream. SoundFlow covers the whole pipeline: stitching short clips into long interactions for data, chunk-level decision training with history review and comprehension-aware silence, and asynchronous FIFO inference that cuts first-frame latency by 4.5×.
StreamAudio-2M
A large-scale streaming instruction-following corpus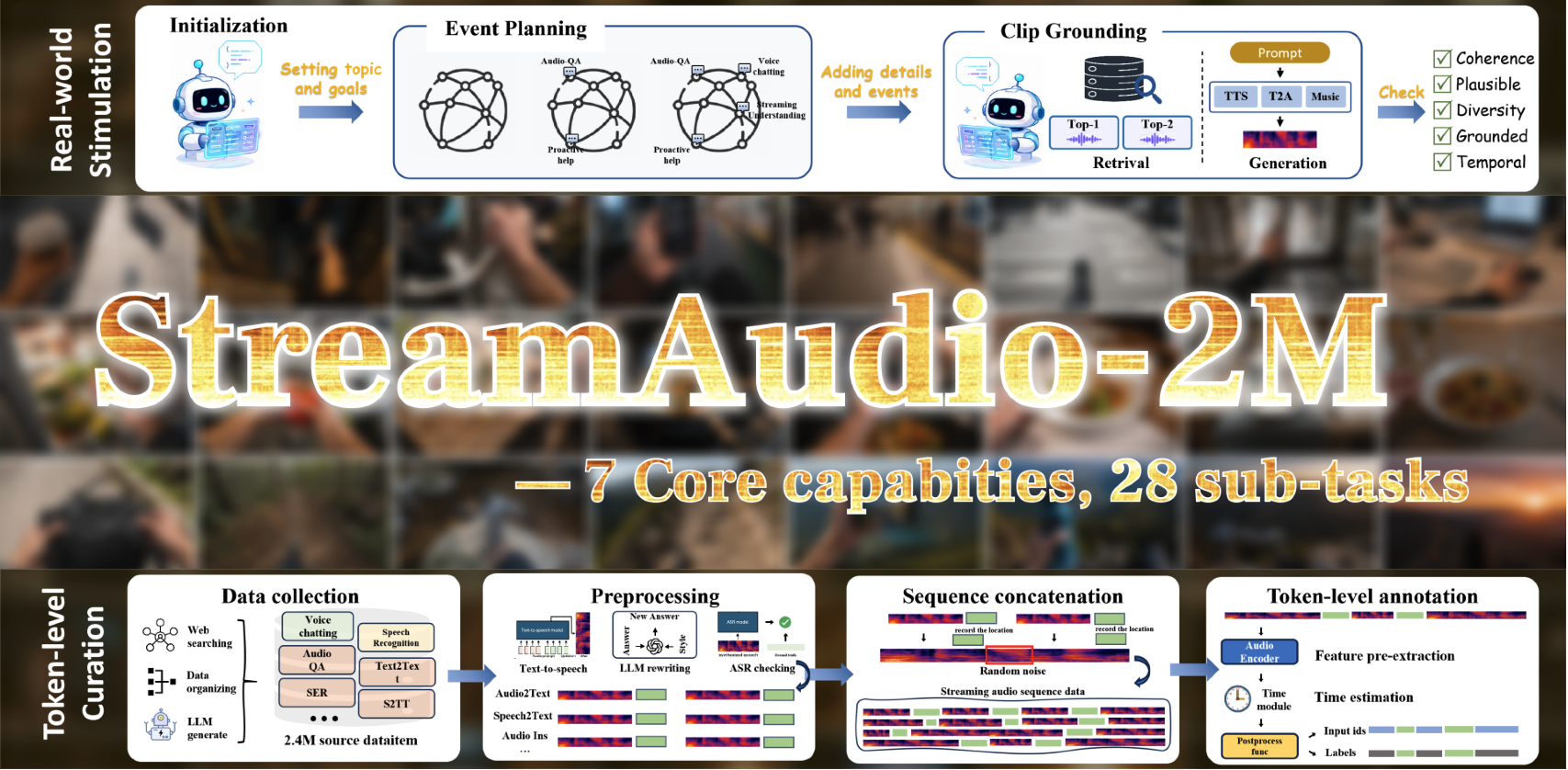
StreamAudio-2M covers seven core capabilities: audio understanding, real-time ASR, speech translation, voice chatting, proactive response, and environment-aware agent. It is built by collecting clips from real-world datasets (AudioSet, CommonVoice, CoVoST2, MOSS, and more), synthesizing text into speech with CosyVoice, then concatenating them into streaming sequences with environmental noise and token-level annotation.
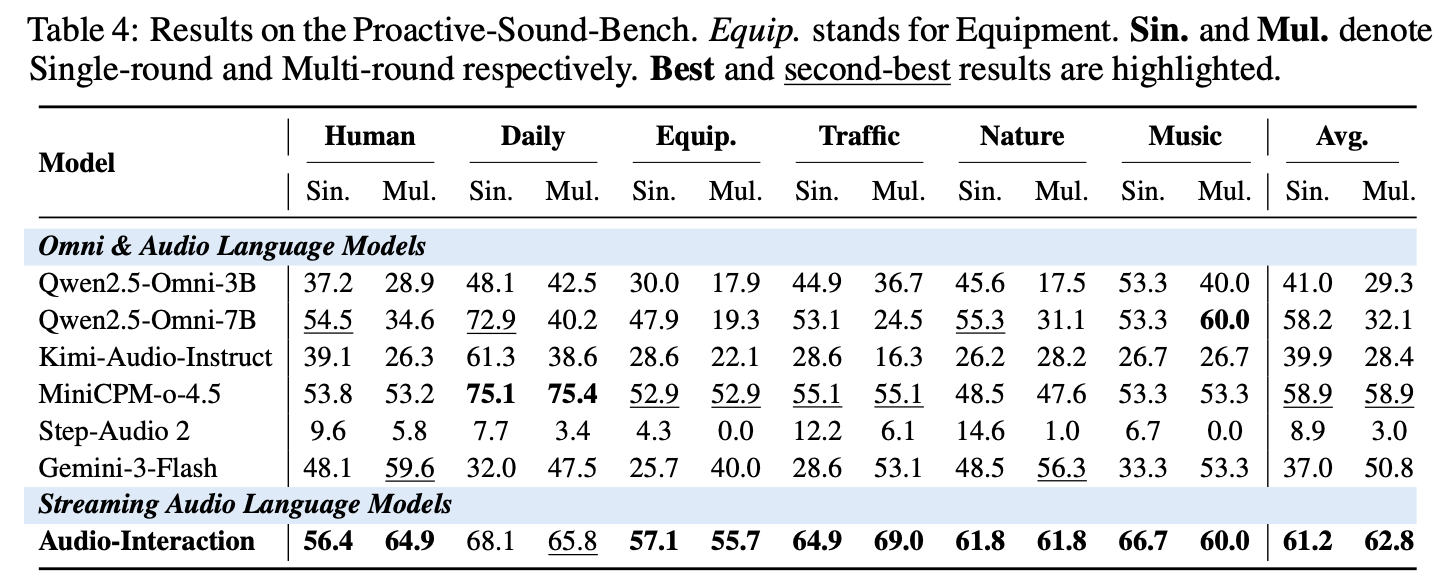
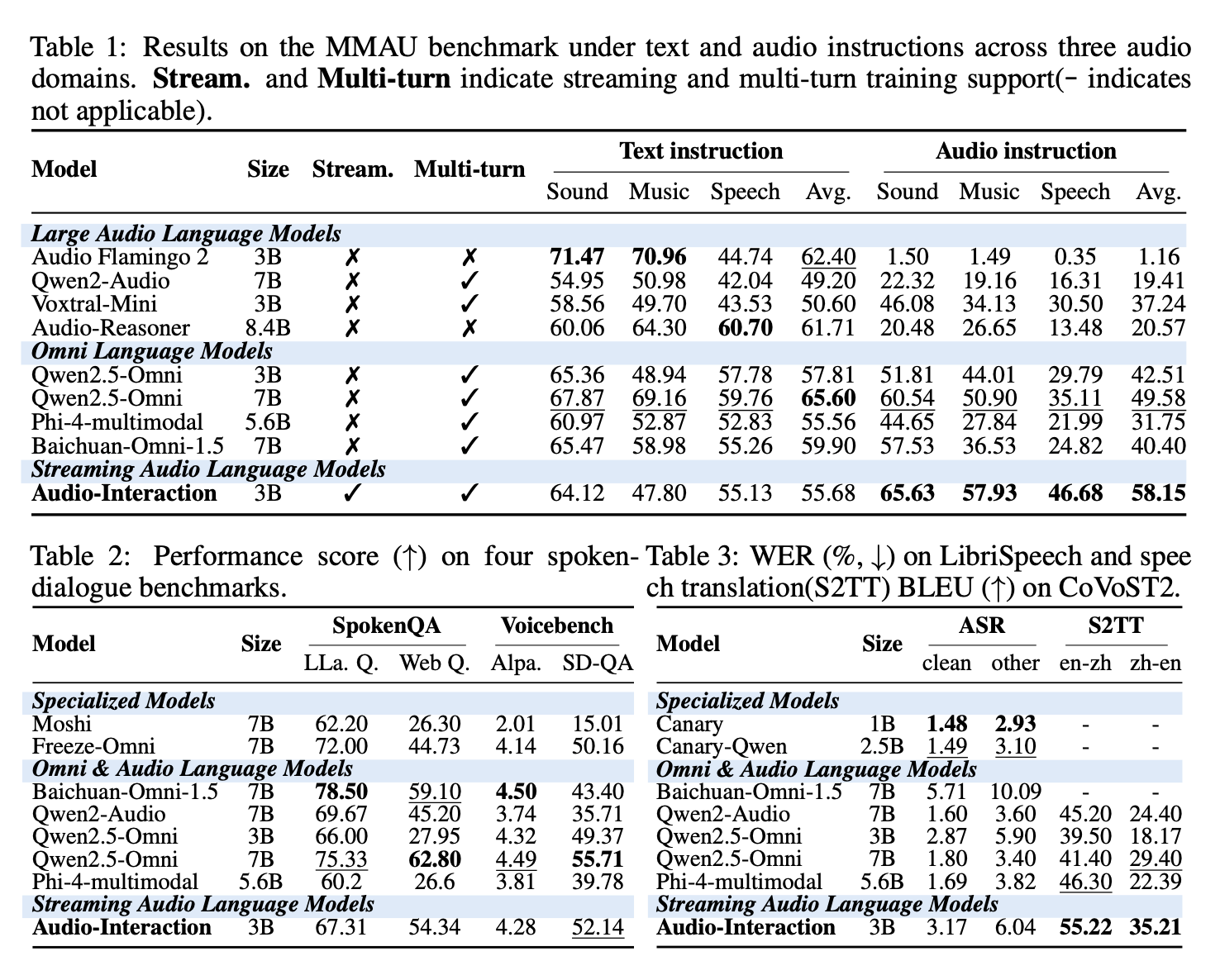
Results
Audio-Interaction keeps its foundational capabilities intact while becoming markedly stronger on speech-driven input, and it shows the strongest proactive intervention of every model we compare against.
Foundation
Basic ability preserved
Offline recognition and translation stay on par with strong baselines, so nothing is lost by going always-on.
Proactive
Best-in-class intervention
The strongest proactive intervention of any model we test: it knows not just what to say, but when to say it.